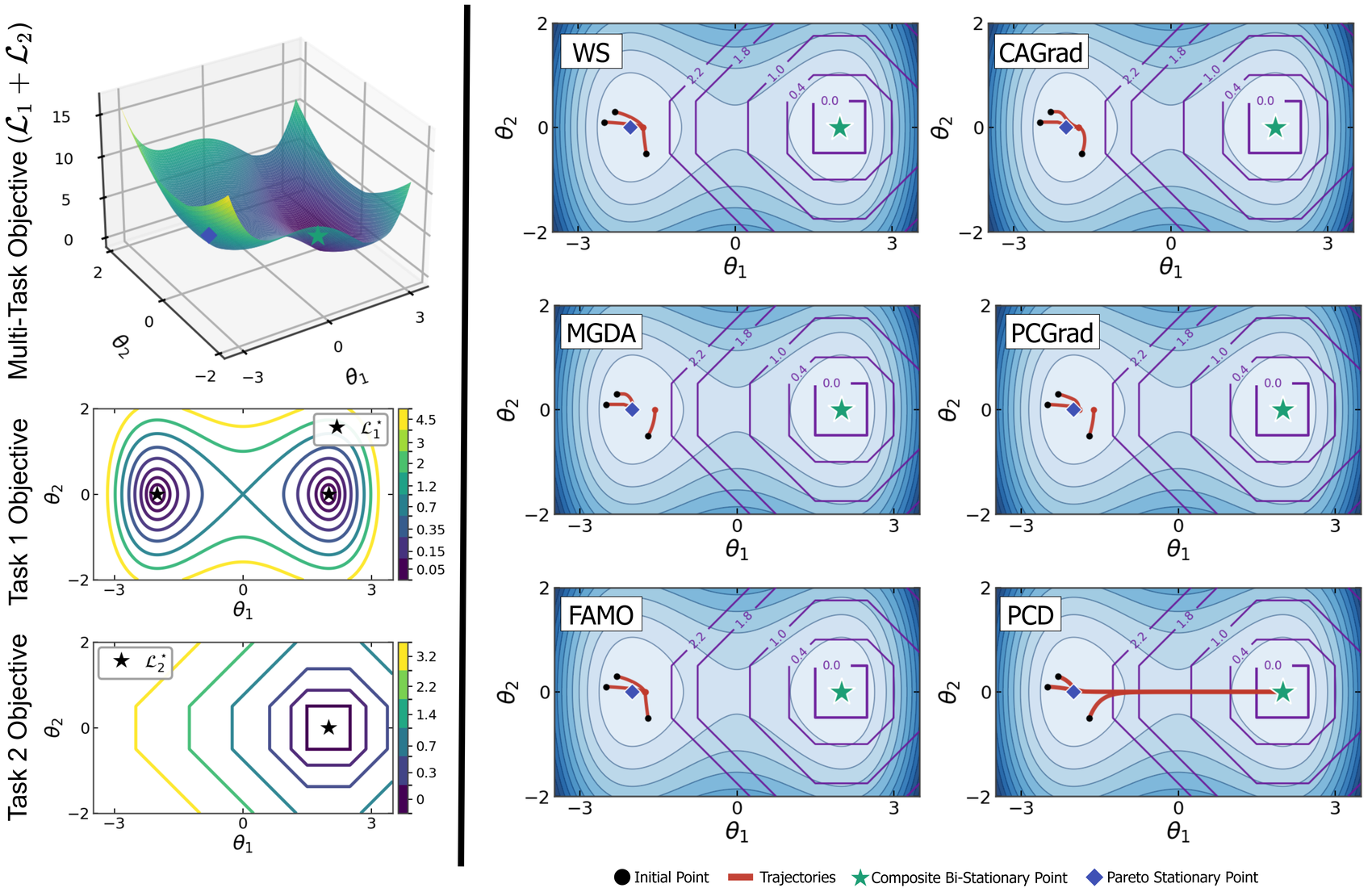
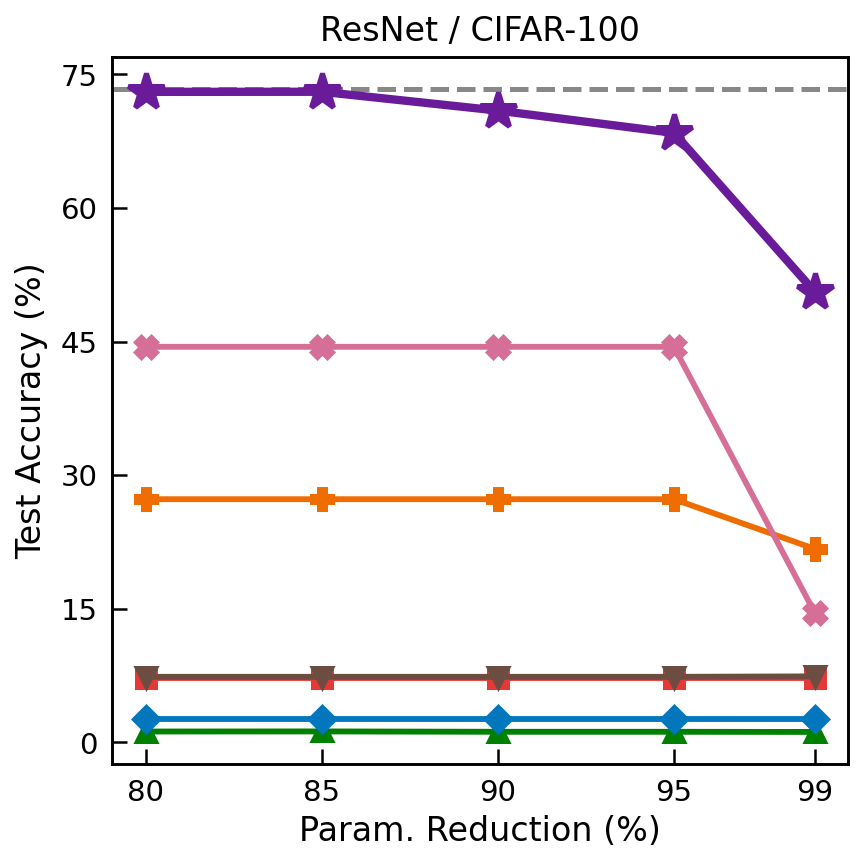
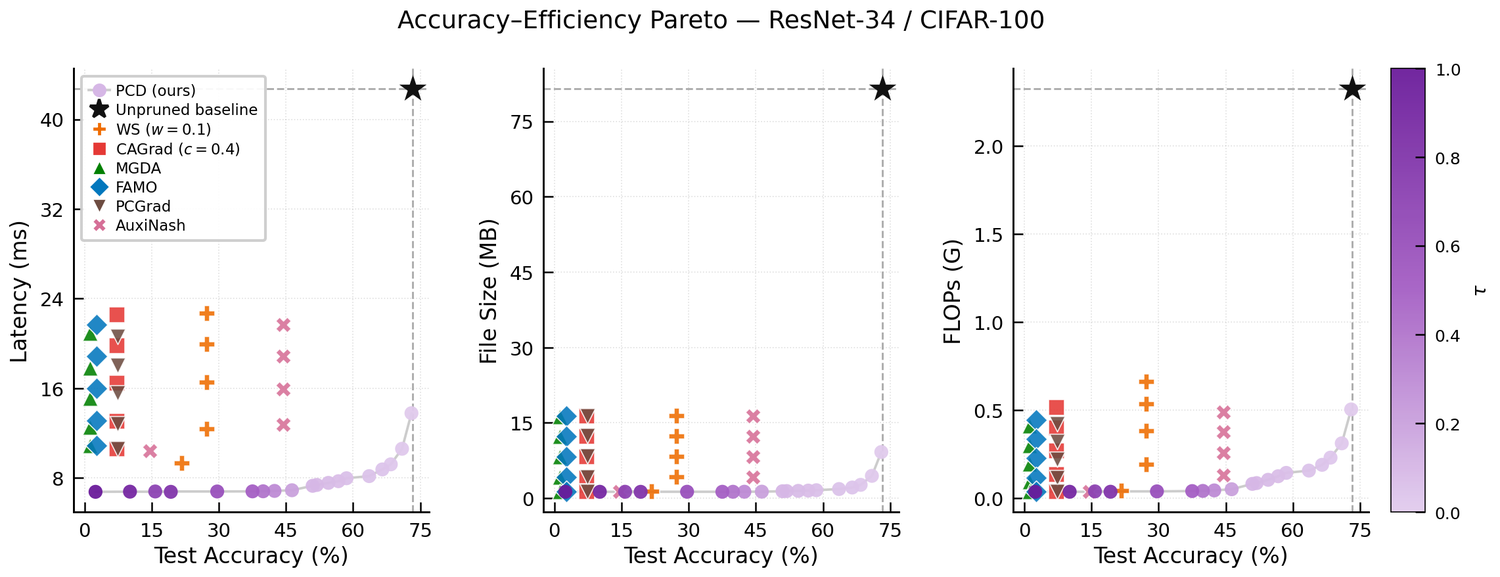
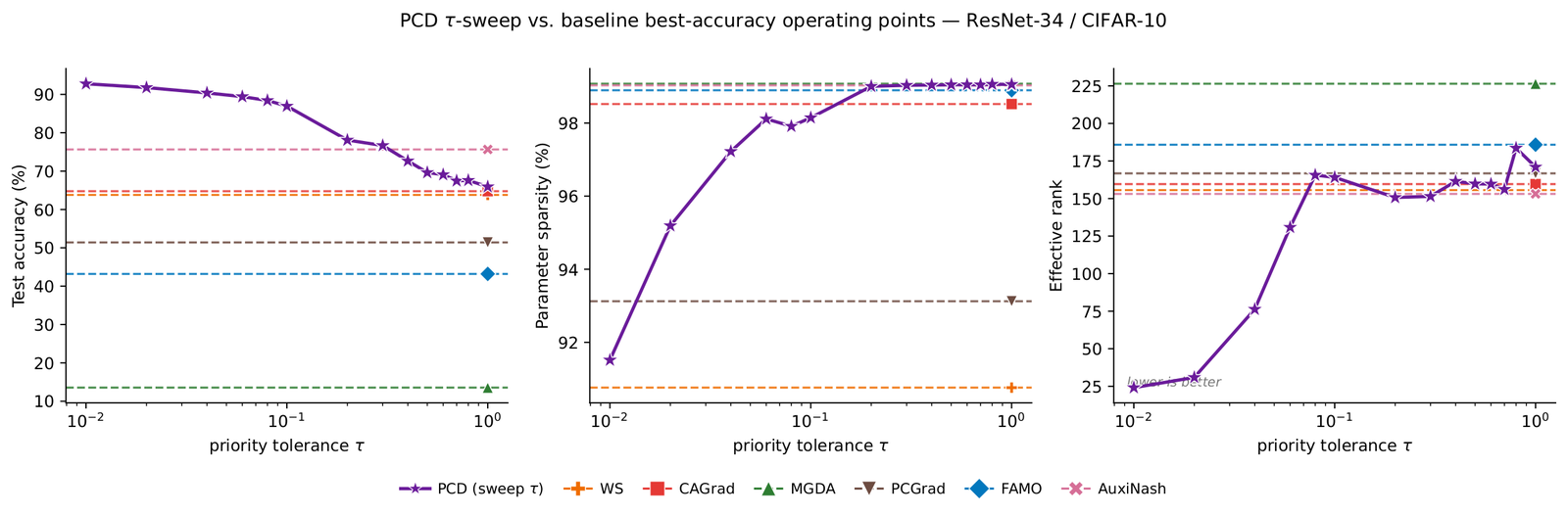
Let g̃1, …, g̃K be the scale-normalized gradients of the primary and secondary objectives. PCD takes the direction closest to the primary gradient that still guarantees a τ-fraction of progress on every secondary:
\[ \mathbf{d}^\star \;=\; \operatorname*{arg\,min}_{\mathbf{d}\in\mathbb{R}^n}\; \bigl\lVert \mathbf{d}-\tilde{\mathbf{g}}_1 \bigr\rVert^2 \quad\text{s.t.}\quad \tilde{\mathbf{g}}_j^{\!\top}\mathbf{d} \;\ge\; \tau\,\bigl\lVert\tilde{\mathbf{g}}_j\bigr\rVert^2 \quad \forall\, j \ge 2 \]
This small convex quadratic program is exactly the Euclidean projection of the primary gradient onto the polyhedron of admissible directions. Its KKT solution has one revealing form:
\[ \mathbf{d}^\star \;=\; \tilde{\mathbf{g}}_1 \;+\; \sum_{j\ge 2}\mu_j^\star\,\tilde{\mathbf{g}}_j, \qquad \mu_j^\star \ge 0 \]
The primary's coefficient is pinned to one; each secondary enters only through a non-negative multiplier that is zero unless its constraint is active. The "anchor" and the "corrections" are built into the construction — not recovered from it. That is the structural break from symmetric methods, which mix g1 and g2 as peers and cannot tell the deliverable from its constraints.
For K = 2 the update is fully closed-form — add exactly the component along g̃2 needed to meet the constraint at equality, and no more. K = 3 is closed-form via Cramer's rule; larger K uses an active-set solver whose O(K²n) cost is dominated by the K backpropagations.
\[ \mathbf{d}^\star = \begin{cases} \tilde{\mathbf{g}}_1, & \tilde{\mathbf{g}}_2^{\!\top}\tilde{\mathbf{g}}_1 \ge \tau\lVert\tilde{\mathbf{g}}_2\rVert^2,\\[6pt] \tilde{\mathbf{g}}_1 + \Bigl(\tau - \dfrac{\tilde{\mathbf{g}}_2^{\!\top}\tilde{\mathbf{g}}_1}{\lVert\tilde{\mathbf{g}}_2\rVert^2}\Bigr)\,\tilde{\mathbf{g}}_2, & \text{otherwise.} \end{cases} \]
Scale invariance. Gradients are normalized by an EMA of their squared norm, so ‖g̃j‖ ≈ 1 in steady state. That makes τ interpretable on [0,1] regardless of loss magnitudes, and the update invariant to per-objective rescaling — a property weighted sum provably lacks.